Static Devirtualization of Themida
Table of Contents
Introduction
Before reading this article I highly recommend studying the following community research on binary deobfuscation.
- https://arxiv.org/pdf/1909.01752
- https://github.com/Colton1skees/Dna/pull/8
- https://github.com/JonathanSalwan/VMProtect-devirtualization
- https://github.com/NaC-L/Mergen
- https://www.youtube.com/watch?v=3LtwqJM3Qjg
- https://github.com/backengineering/vmp2
- https://back.engineering/blog/17/05/2021/
- https://www.youtube.com/watch?v=vYAJCfafYTY
- https://www.youtube.com/watch?v=KYQOtGiH9pQ
- https://github.com/r3bb1t/bin_lift
- https://nac-l.github.io/2025/01/25/lifting_0.html
- https://blog.thalium.re/posts/llvm-powered-devirtualization/
- https://github.com/avast/retdec
- https://github.com/ergrelet/themida-unmutate
- https://github.com/lifting-bits/remill
This article demonstrates devirtualization of CodeVirtualizer/Themida protected code, however the techniques described here apply to pretty much every virtual machine based obfuscator. Only requiring some minor modifications to support each of them. The following is a non-exhaustive list of obfuscators that can be reduced using the technique described in this article.
- https://vmpsoft.com/
- https://www.oreans.com/themida.php
- https://github.com/vxlang/vxlang-page
- https://github.com/snowsnowsnows/EagleVM
- https://github.com/dmaivel/covirt
- https://github.com/noahware/binprotect
Themida Architecture Analysis
Themida’s virtual machine architecture differs from VMProtect primarily in its support for nested virtualization. This is made possible by the fact that the VM context and virtual stack live inside the binary itself rather than on the native stack as they do in VMProtect. This article will not go deep on the architecture since it is largely not relevant to the devirtualization approach. The only VM-specific components that matter here are virtual branching and VMEXIT behavior, both of which are covered in their own sections. For a thorough breakdown of the Themida architecture, see this research.
Warning To The Wise
Pattern matching VM handlers back to x86 instructions is not an approach I recommend. I have tried it, and it does not scale. Any small change the protector vendor makes to handler layout, opcode tables, or dispatch logic can silently break your tooling across an entire version range. The more your implementation depends on VM-specific behavior, the more fragile it becomes.
The approach presented in this article deliberately minimizes VM-specific knowledge. That is what makes it work across a wide range of Themida versions. That said, studying the VM architecture is still worthwhile, not to pattern match against it, but to orient yourself within it and make informed decisions about how to guide the symbolic evaluation engine.
The vast majority of devirtualization work is done by a handful of general optimizations. VM-specific knowledge only becomes necessary when dealing with control flow, specifically virtual branching and virtualized calls.
Guided Symbolic Evaluation
The core idea is to lift native instructions into a malleable intermediate representation and drive the lifting process forward by concretizing control flow as optimizations resolve unknown branch destinations. Back Engineering Labs maintains its own binary lifting and recompilation engine for this purpose called BLARE2. It sports a custom SSA IR with support for AMD64 and ARM64, along with a full pass system, optimizer, instruction selector, register allocator, and linker. That last part is what separates it from most lifting frameworks: BLARE2 can lower optimized IR back to native code and reinsert it into the binary, producing output that is near 1:1 with the original. Anyone looking to follow the techniques in this article can get most of the way there with Triton or an LLVM-based lifter like Remill. Both are capable of producing clean optimized IR. The gap is on the backend: getting LLVM to emit tight, well-behaved native code that reinserts cleanly.
Lifting starts with all registers and flags symbolic. From there, instructions are disassembled and lifted until the next instruction pointer cannot be determined. What happens next depends on the control flow instruction. A lifted ret means the last store to RSP is the next IP. When an address genuinely cannot be concretized, it means one of two things: either the optimizations have not run far enough, or the branch has multiple real destinations, as is the case with a virtualized JCC.
Concretizing Stack Pointer
At the start of symbolic evaluation, all registers and flags are symbolic except for the stack pointer, which is given a concrete initial value. This is a deliberate design choice rather than a strict requirement. Keeping RSP concrete means the existing load/store propagation machinery handles stack accesses automatically, and any arithmetic that adjusts the stack pointer can be constant folded without any special casing. The alternative is keeping RSP symbolic and writing dedicated stack propagation logic, which is more work for no meaningful gain in the context of devirtualization.
The tradeoff is that functions with dynamic stack allocations, think alloca or compiler-generated variable-length arrays, are not supported by this approach since the stack displacement is no longer statically knowable. In practice this is rarely a problem. Dynamically allocated stack frames are uncommon in the kinds of functions that tend to get virtualized, so the simplicity of a concrete RSP is worth the limitation.
Optimizations
Fully reducing Themida or VMP virtualization does not require an exhaustive suite of compiler optimizations. In practice, a small set of passes running together to convergence is enough to collapse the entire VM scaffolding. The following sections cover each one and explain how it contributes to devirtualization.
The passes are not independent. A bytecode load gets promoted to a constant, which lets the decryption arithmetic around it fold away, which produces a concrete handler index, which lets the handler table lookup resolve, which exposes the next handler address as a constant. Each pass feeds the next, and the VM scaffolding unravels as a consequence of all of them running together.
Constant Promotion & Memory Modeling
Data loaded from memory frequently feeds into indirect jump computations, and VM bytecode is the most important example of this. When the lifter encounters a load from a bytecode address, that value needs to be promoted to a constant so the rest of the optimization passes have something concrete to work with. Once a bytecode load is promoted, constant folding can run on the decode arithmetic that surrounds it. The handler decryption logic, the opcode table indexing, the VPC update math, all of it progressively folds away until the only thing left is a concrete handler address. That address is then used to continue lifting.
The load store propagation logic in BLARE2 is configurable. A programmer specifies which memory ranges inside the binary are safe to promote from, which keeps VM-private constant promotion from accidentally touching user data. The pass also tracks prior stores, so if a store to address 0x5000 occurs and a load of 0x5000 follows, the SSA value from that store is forwarded rather than pulling from the original image. Propagation is modeled at the byte level, so overlapping stores are handled correctly. A narrow store that partially overlaps a wider load is composed properly rather than silently producing a stale or incorrect value. There are two failure modes worth keeping in mind. Promoting a load from an address that gets written before the load is reached will produce incorrect results, which is why store tracking exists. The other risk is over-promotion: if a load reflects original program semantics rather than VM scaffolding, replacing it with a constant destroys those semantics. The configurable range policy is what separates the two cases.
Constant Folding
When all operands of an expression are known constants, the expression itself can be replaced with its result. There is no reason to carry 10 + 10 through the IR when it can just be 20. This applies to all binary and arithmetic operations: addition, subtraction, multiplication, bitwise AND, OR, XOR, shifts, and so on. For devirtualization, the important detail is that this pass needs to run until convergence. A single pass may fold one expression into a constant that then makes a previously non-constant expression fully constant, which enables another fold, and so on. Each optimization pass feeding into the next is what causes the VM scaffolding to progressively collapse. Bytecode decode arithmetic folds away, handler table indices become concrete, and dispatch logic disappears, all as a consequence of constant folding running to a fixed point alongside the other passes.
Dead Store Elimination
Dead store elimination is generally unsafe to apply broadly. A store that looks unused may have real side effects: a kernel routine writing to the same MMIO address twice can trigger distinct hardware actions, and exceptional control flow can observe stores that appear dead along normal paths. Blindly removing stores breaks things. The reason it is safe here is that the stores we are targeting are scoped to VM-private memory. Themida uses its own section for the virtual machine context, virtual stack, and related scaffolding. None of that memory is observed by the original program. Once lifting has reached a VMEXIT, any store that only ever touched the Themida section is provably dead from the perspective of the recovered function and can be removed. Skipping this pass has a visible cost. VM handlers constantly shuffle state through the context and virtual stack, and without elimination those stores persist as dangling expressions in the IR that have no consumer and no path to a native-visible output. Combined with the dead dependency analysis pass, this is what produces IR that actually looks like a function rather than a VM interpreter
Instruction Combination
Instruction combination simplifies expressions by recognizing algebraic identities and collapsing operations that have knowable outcomes regardless of their inputs. The goal is to reduce the IR down to the smallest expression that preserves the original semantics.
These identities matter for devirtualization because VM handlers are full of this kind of noise. Obfuscated code frequently introduces arithmetic that cancels itself out, redundant masking operations, and identity multiplications inserted purely to obscure intent. Instruction combination running to convergence progressively peels those layers away, and the simplified expressions it produces feed directly into constant folding and branch folding. An expression that looks complex after lifting often reduces to a single constant once a few of these rules have fired.
Branch Folding
When the preceding optimizations have done their job, flag computations should resolve to either a constant or undefined. Any branch that depends on constant flags has a statically knowable destination, so the opaque branch target can be eliminated entirely.
VMEXIT Behavior
Because the stack pointer is concretized at the start of lifting, the initial RSP value is always known. When the lifter encounters a return instruction with RSP at initRSP - 0x10, that is a VMEXIT-CALL. Themida and VMP both use this pattern: the call target is placed at RSP and the return address is placed at RSP + 0x8, accounting for the 0x10 displacement. At that point we emit a call operation in the IR. The call target may be symbolic if the original code performed an indirect call, so that case needs to be handled explicitly. It is also worth noting that this pattern is not CET compliant, since the return address on the stack was not placed there by the vmenter stub.
Not every VMEXIT is a call. The displacement from the initial RSP is what distinguishes them. A return to the original function epilog, an unsupported instruction exit, and a call-shaped exit all produce different stack pointer values, and the control flow match logic uses those differences to classify each exit correctly.
Virtualized Control Flow
Every virtual instruction pointer encountered during lifting needs to be recorded. The reason is simple: when we discover backedges later, we need to recognize them as loops rather than unrolling them indefinitely. Failing to track VIP means virtualized loops get unrolled, and the IR explodes.
With VMProtect, tracking VIP is straightforward. The bytecode encodes the next handler address, so the last module load that feeds into the indirect jump computation is by definition the current VIP. In BLARE2, we walk the IR DAG backwards from the SSA value holding the jump or return target and find that last load. That gives us VIP.
Themida’s approach to virtualized conditional branches is different from VMP’s, and this is one of the few places where VM-specific knowledge is actually required. Nearly everything covered so far is generic and applies equally to VMP and other VM-based protectors, but the VJCC handler is a Themida-specific construction.
In Themida’s VJCC handler, the condition is evaluated first and the result written to a branch_taken_flag in the VM context. VIP is not advanced until the end of the handler, after that flag is set. This means symbolic execution hits the branch fork before VIP is resolved. Both paths need to be explored, and the correct VIP for each path has to be traced through the conditional VPC update logic at the bottom of the handler rather than read from a single load. The simple heuristic that works for VMP, where VIP is just the last module load feeding the indirect jump computation, does not apply here. You have to follow the branch_taken_flag through to where VIP diverges.
Dead Dependency Analysis Pass
Before lowering, we need to know which registers and flags are actually live coming out of the virtualized region. The way to determine this is to collect the set of registers and flags that are clobbered by native code immediately after the VM exits. Anything clobbered there is dead from the VM’s perspective and doesn’t need to be computed.
Without this pass, symbolic expressions dangle in the IR with nothing to anchor them. Take ZF as an example: if it’s symbolic and depends on some VM-internal computation, the IR will carry the full expression tree for ZF even if the very next native instruction overwrites it.
Stack Pointer Rewrite Pass
Because the stack pointer was concretized at the start of lifting, the simplified IR will have loads and stores targeting constant stack addresses. This pass rewrites those accesses back into RSP-relative form before lowering. One thing to verify here: no stack references should be negative, as that would mean something is reaching down into the red zone.
Lowering IR
With clean IR in hand, the next step is lowering it back to the original ISA. Lowering covers instruction selection, register allocation, assembly, and linking the recovered code back into the binary. This is handled by BLARE2, an in-house framework that has years of research behind it and supports both devirtualization and obfuscation.
The critical constraint during lowering is register pressure. If the register allocator spills, the devirtualized code gets its own stack frame alongside the original function’s stack frame. That immediately causes problems: stack-passed arguments to calls inside the devirtualized region will be misread by IDA, Binary Ninja, and anything else an analyst loads the binary into. The goal is executable output that is as close to the original as possible and loads cleanly in any disassembler.
This is also why I’m skeptical of LLVM-based devirtualization frameworks for this specific problem. Getting LLVM to emit tight, well-behaved native code that reinserts cleanly into a binary is a project in itself. You can absolutely get readable LLVM IR out of a lifting pipeline, but going the rest of the way to clean, reinsertable native code requires fighting the LLVM framework at every step.
Results
Below are two images: the first shows the original function in IDA before virtualization, and the second shows the same function after devirtualization.
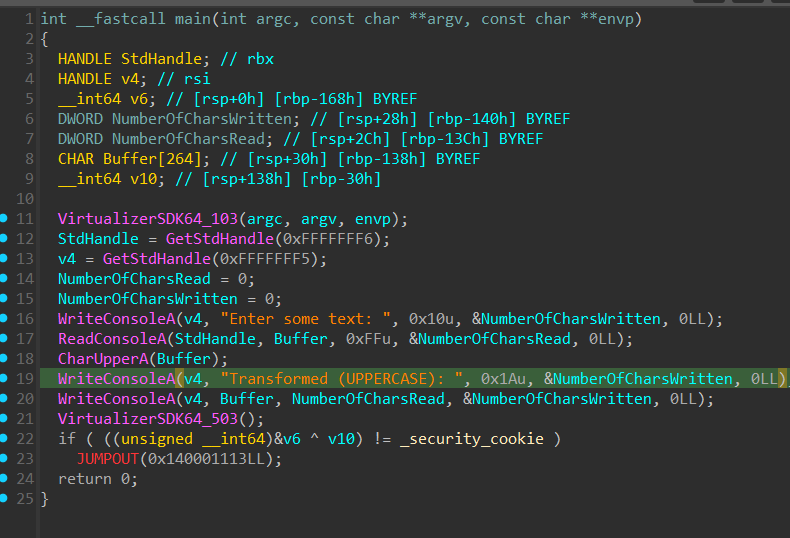
Original code in IDA (before virtualization)
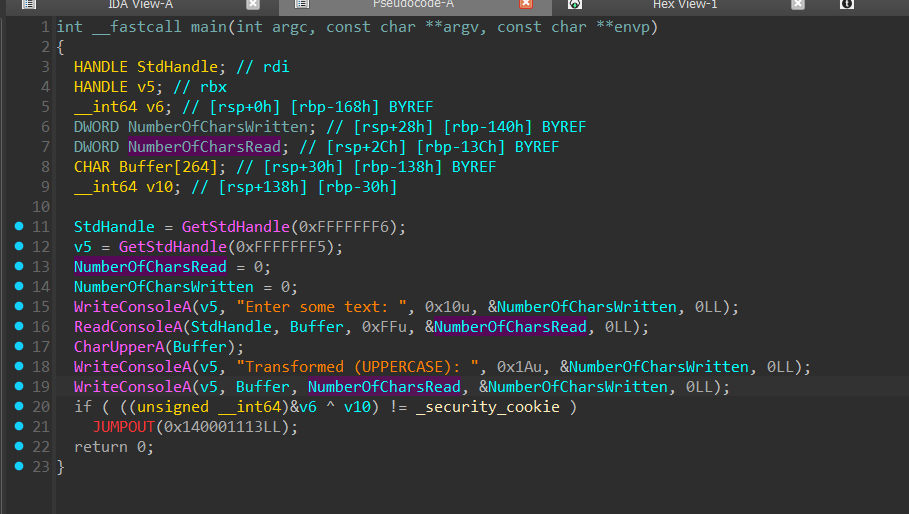
Code after devirtualization
The devirtualized output is functionally 1:1 with the original. However, you may notice that different instructions and registers have been selected by the backend. This is a result of the register allocator and instruction selector making different choices, but crucially, no register spilling has occurred. The recovered code remains as tight and clean as the original, with no extraneous stack frames or artifacts.
Importantly, the devirtualized code is not just structurally similar, it is fully executable. The recovered function can be run as native code, loading cleanly in disassemblers and behaving identically to the original implementation.
For those interested in further analysis or validation, a GitHub repository will be provided containing the original binary, the virtualized binary, and the devirtualized binary. This will allow readers to examine and compare the results directly.
Repository link: https://github.com/backengineering/themida-devirt
Preventing Symbolic Evaluation
For an obfuscator to defeat symbolic evaluation, it needs to prevent indirect jump destinations from ever becoming concrete. A simple way of preventing the branch destination from becoming concretized is by encoding it as an MBA expression with opaque values, this will prevent constant folding from reducing the expression. This worked well for a while, but MBA expressions of the kind used to hide branch targets are now trivially reducible using the techniques described in this presentation. Stronger techniques exist that make symbolic evaluation generically infeasible. CodeDefender implements these in its heavier protection tiers, though the specifics are outside the scope of this article.